
Process Mining überwindet die Grenzen der traditionellen Workflow-Automatisierung. Dieser faktenbasierte Ansatz hilft dabei, bisher unentdeckte Reibungen in den Bereichen Performance und Compliance aufzudecken. Zusätzlich ergänzt Process Mining beispielsweise Robotic Process Automation (RPA) und andere Automatisierungsinitiativen, ohne dabei typische Fehler zu machen.
Process Mining entstand Ende der 1990er-Jahre als Reaktion auf die Misserfolge der klassischen Workflow-Automatisierung. Viele Nutzer – so auch ich – glaubten, dass Workflow-Management-Systeme bald so verbreitet und etabliert sein würden wie Datenbank-Management-Systeme. Die Annahme war, dass man durch die bloße Prozess-Modellierung Informationssysteme erzeugen kann, die diese Prozesse unterstützen und automatisieren.
Straight-Through-Processing (STP)
Ein in den 1990er-Jahren gebräuchlicher Begriff dafür war „Straight-Through-Processing“ (STP). STP beschreibt den Wunsch, Fälle ohne menschliches Zutun bearbeiten zu können. Die Realität sah leider anders aus: Unsere Längsschnittstudie dazu zeigt, dass die Hälfte der Workflow-Management-Projekte scheiterte. So gaben die meisten Unternehmen nach einer ersten Phase des Optimismus die Idee wieder auf. Das Hauptproblem war, dass reale Prozesse viel komplexer sind, als es die einfachen Prozessmodelle vermuten ließen. Selbst vermeintlich unkomplizierte Prozesse wie Order-to-Cash (O2C) und Purchase-to-Pay (P2P) können Tausende von Varianten aufweisen. Die relevanten Informationen dazu sind teilweise in Dutzenden von Datenbanktabellen gespeichert. Es ist also offensichtlich, dass diese Komplexität nicht durch ein idealisiertes Prozessmodell dargestellt werden kann.
Diese Probleme haben die Entwicklung der ersten Process-Mining-Algorithmen angestoßen. Lange Zeit war meine Forschungsgruppe an der Technischen Universität Eindhoven die Einzige, die das Problem systematisch erforschte. Anstatt Prozessmodelle künstlich zu modellieren, entdeckten wir die tatsächlichen Prozesse in den Daten selbst. So konnten wir Abläufe mit diesen Daten realistisch beschreiben. Außerdem entwickelten wir Techniken für das sogenannte Conformance Checking, um Leistungs- und Compliance-Probleme aufzudecken. All diese Techniken wurden zunächst in dem Open Source Process-Mining-Framework ProM implementiert. Infolge unserer akademischen Bemühungen entstanden in den folgenden Jahren zahlreiche Process-Mining-Start-ups. Diese entwickelten eine Reihe von Tools, die das Thema Process Mining und seine Anwendung deutlich attraktiver machten. Von Beginn an zeigte sich, dass die tatsächlichen Betriebsprozesse oftmals von den erwarteten Prozessen abweichen.
Die meisten Prozesse folgen einer sogenannten Pareto-Verteilung, das heißt, 80 Prozent aller Cases werden wie erwartet ausgeführt, und nur 20 Prozent weichen davon ab. Diese 20 Prozent verbrauchen jedoch 80 Prozent der Ressourcen einer Organisation und verursachen Nacharbeit, Korrekturmaßnahmen und Exception Handling. Mit Process Mining können solche abweichenden Fälle diagnostiziert und Verbesserungen angestoßen werden.
Von Process Discovery zu Conformance Checking
Ursprünglich konzentrierten sich kommerzielle Process-Mining-Tools auf Process Discovery, das heißt das Erkennen und Abbilden von Prozessen und die automatische Bottleneck-Analyse. Dies geschah typischerweise unter Verwendung von Offline-Event-Logs und einfachen Darstellungen wie dem Directly-Follows Graph (DFG). Die heute führenden Process-Mining-Tools hingegen bieten Conformance Checking, bessere Discovery-Techniken, Predictive Analytics, vergleichendes Process Mining und anpassbare Dashboards, die kontinuierlich aktualisiert und von allen Prozessbeteiligten genutzt werden.
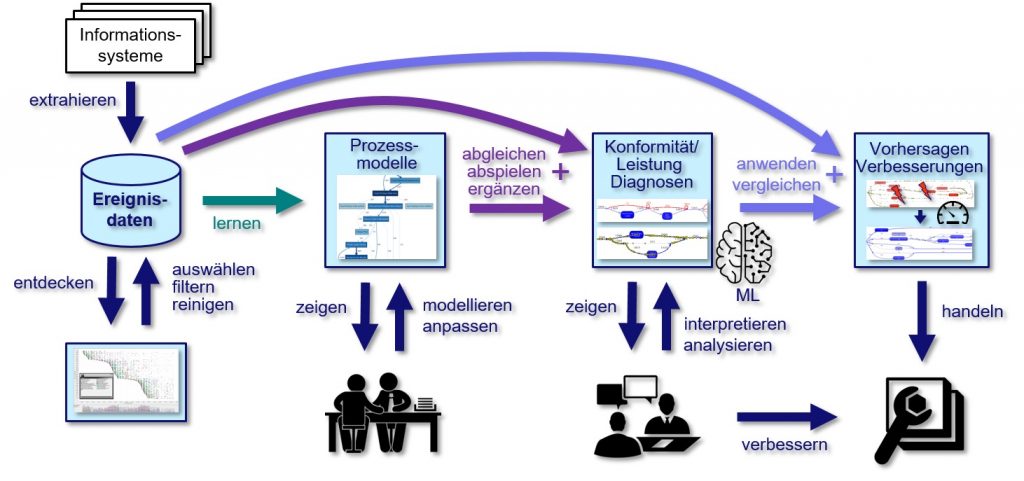
Die Schritte des Process Mining
Überblick über die grundlegenden Schritte und Möglichkeiten des Process Mining
Obwohl Process Mining ursprünglich dazu gedacht war, auftretenden Problemen bei der Automatisierung von Arbeitsabläufen entgegenzuwirken, ermöglicht es jetzt neuartige Automatisierungsformen. Beispielsweise unterstützt Process Mining den Ansatz der Robotic Process Automation (RPA) auf zwei Arten:
- Identifizierung von Routinen, bei denen Maschinen repetitive Arbeiten von Menschen übernehmen können, und
- Überwachung des korrekten Verhaltens von Maschinen und der gesamten Organisation der Arbeitsabläufe. Während RPA Aufgaben auf eine Bottom-up-Art automatisiert, kann Process Mining den gesamten End-to-End-Prozess verbessern (mit oder ohne zusätzliche Unterstützung durch RPA).
Aktionsbasiertes Process Mining
Eine weitere Entwicklung ist das aktionsorientierte Process Mining, bei dem korrigierende Workflows durch Process-Mining-Diagnosen ausgelöst werden. Die Event-Log-Daten können aus verschiedenen Quellsystemen stammen (z. B. SAP, Salesforce oder ServiceNow). Wohlgemerkt sind die korrigierenden Workflows nicht dazu da diese Quellsysteme zu ersetzen, sondern um Leistungs- und Compliance-Probleme zu beheben. Dies ist durch Cloud-basierte Automatisierungstools auf Low-Code-Basis möglich. Process Mining ergänzt also neue Formen der Automatisierung, ohne den klassischen Fehler zu machen, die Realität zu sehr zu vereinfachen.
 Der Autor: Prof.Dr.ir. Wil van der Aalst ist Professor an der RWTH Aachen University und leitet die Gruppe Process and Data Science (PADS). Darüber hinaus ist er in Teilzeit am Fraunhofer- Institut für Angewandte Informationstechnik (FIT) und der Universität Tilburg tätig und hat eine beratende Funktion in mehreren Unternehmen, darunter Celonis, Fluxicon und aiConomix. Er ist außerdem IFIP Fellow, IEEE Fellow, ACM Fellow und hält mehrere Ehrendoktortitel.
Der Autor: Prof.Dr.ir. Wil van der Aalst ist Professor an der RWTH Aachen University und leitet die Gruppe Process and Data Science (PADS). Darüber hinaus ist er in Teilzeit am Fraunhofer- Institut für Angewandte Informationstechnik (FIT) und der Universität Tilburg tätig und hat eine beratende Funktion in mehreren Unternehmen, darunter Celonis, Fluxicon und aiConomix. Er ist außerdem IFIP Fellow, IEEE Fellow, ACM Fellow und hält mehrere Ehrendoktortitel.