
Geschäftsprozessmodelle sollen Unternehmen dabei helfen, ihre Prozesse zu verstehen und zu verbessern. Mit Process Mining ist es möglich, solche Modelle automatisch aus Logdaten von IT-Systemen abzuleiten. Allerdings müssen diese Daten dazu zunächst wohldefinierten Prozessen zugeordnet werden und einen geeigneten Abstraktionsgrad besitzen. Andernfalls sind die abgeleiteten Prozessmodelle für den Anwender unbrauchbar.
Das Process Mining bietet eine vielfältige Sammlung von Methoden und Algorithmen zur Analyse von Prozessausführungsdaten. Diese ermöglichen nicht nur die automatische Herleitung von Prozessmodellen aus Daten, sondern auch den Abgleich von Ausführungsdaten mit bereits bestehenden Prozessmodellen. Die grundlegende Annahme dabei ist, dass die Daten bereits in einem für das Process Mining geeigneten Format vorliegen.
Dieses Event-Log-Format hat gewisse Anforderungen. So muss zum einen jeder Eintrag einer Prozessaktivität zugeordnet werden können. Zum anderen muss ersichtlich sein, für welchen Fall – z.B. für welche Kundenbestellung – eine gegebene Aktivität ausgeführt wurde. Zudem müssen die Einträge zeitlich geordnet sein, so dass die Ausführungsreihenfolge der Aktivitäten anhand der Daten erkennbar ist. Diese Anforderungen sind in der Realität oftmals nicht erfüllt. Vielmehr befinden sich die Prozessdaten in ERP-Systemen, Datenbanken oder Excel-Dateien und haben unterschiedlichste Formate.
Dieser Umstand erfordert eine Vorverabeitung der Daten, um die Methoden des Process Mining zu ermöglichen. Hierbei wird zwischen drei Schritten unterschieden: Bei der Datenextraktion geht es darum, aus Datenspeichern diejenigen Elemente zu identifizieren und zu extrahieren, die später die Grundlage für Event-Logs bilden. Die Datenkorrelation befasst sich mit der Zuordnung der extrahierten Elemente zu ihren jeweiligen Fällen. Die Aufgabe der Datenabstraktion ist es schlussendlich, die extrahierten Elemente gegebenenfalls zusammenzufassen, um einen geeigneten Abstraktionsgrad zu erreichen.
Methoden zur Datenextraktion, -korrelation und -abstraktion
Liegen die zu analysierenden Daten in einer Datenbank vor, können sogenannte Redo-Logs dabei helfen, prozessrelevante Daten zu extrahieren. Redo-Logs protokollieren die Änderungen, die an der Datenbank vorgenommen werden. Solche Änderungen sind etwa das Einfügen, Ändern oder Entfernen von Objekten und Relationen. Auf Basis dieser Änderungen kann ein Prozessverständiger nun Prozessaktivitäten sichtbar machen. Beispielsweise kann definiert werden, dass die Aktivität des Zusammenstellens einer erhaltenen Bestellung im Redo-Log sichtbar wird durch das Entfernen mehrerer Objekte, die die einzelnen Produkte der Bestellung repräsentieren.
Die so identifizierten Aktivitäten müssen allerdings noch mit ihren jeweiligen Fällen korreliert werden, da durchaus mehrere Bestellungen gleichzeitig bearbeitet werden könnten. Im einfachsten Fall enthalten alle Objekte desselben Falls denselben Wert für ein bestimmtes Attribut. In anderen Fällen müssen mehrere Attribute miteinander kombiniert werden, um zu einer eindeutigen Korrelation zu gelangen. Zum Beispiel könnte für eine Bestellung die Kundennummer oder aber der Name und die Adresse zur Korrelation dienen. Nicht zuletzt stehen auch Algorithmen zur Verfügung, die das Bestimmen von Korrelationsattributen automatisieren.
Oftmals besitzen die von Systemen aufgezeichneten Daten einen Abstraktionsgrad, der deren Verständnis im Kontext von Prozessen und Wertschöpfungsketten erschwert. Daher müssen Abstraktionsmethoden angewendet werden, um Daten beispielsweise durch das Zusammenfassen für Anwender interpretierbar zu machen. Simple Verfahren bedienen sich hier der Zeitstempel der Daten. Falls diese nämlich sehr dicht beieinander liegen, lässt dies vermuten, dass sie zur selben Prozessaktivität gehören. Solch eine Situation wurde bereits oben beschrieben als mehrere Redo-Log-Einträge zu einer Aktitivität zusammengefasst wurden. Komplexere Abstraktionsmethoden betreiben zudem eine linguistische Analyse der Daten. So können auch Daten, die eine semantische Relation wie z.B. Synonymität aufweisen, kombiniert werden.
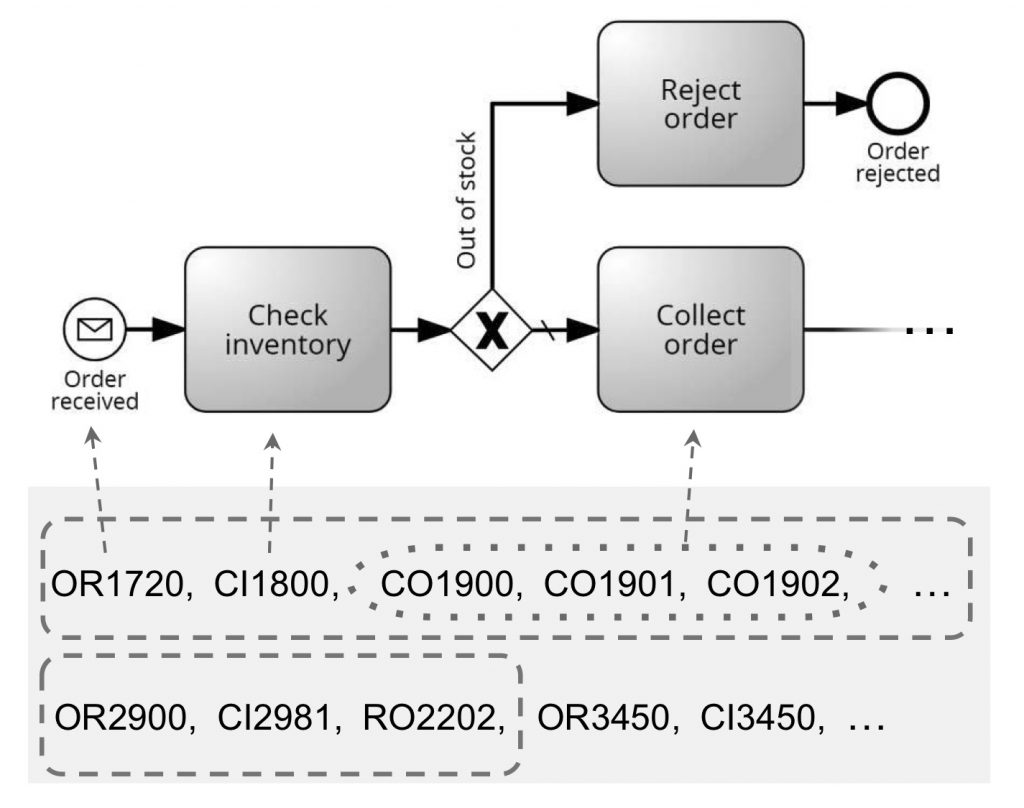
Korrelation und Abstraktion von extrahierten Daten
Die gezeigte Abbildung fasst die Datenextraktion, -korrelation und -abstraktion zusammen. Hier werden extrahierte Daten einem bestehenden Prozessmodell zugeordnet. Die gestrichelten Rechtecke zeigen die Korrelation von Daten zu Fällen des Prozesses, während das Oval zeigt, wie durch Abstraktion mehrere Daten derselben Prozessaktivität zugeordnet werden.
Schlussendlich sind die Methoden der Datenextraktion, -korrelation und -abstraktion also ein wichtiger Bestandteil eines erfolgreichen Process Mining Projekts, da sie die Grundvoraussetzung für viele Algorithmen dieses Bereichs schaffen – ein wohldefiniertes Event-Log. Ist dies nicht gegeben, kann Process Mining nicht sinnvoll betrieben werden und liefert unbrauchbare Ergebnisse.
 Der Autor: Kimon Batoulis ist wissenschaftlicher Mitarbeiter und Doktorand in der Business Process Technology Group des Hasso-Plattner-Instituts. Dort unterrichtet er seit über vier Jahren Process Mining und Business Process Management. In seiner Forschung beschäftigt er sich zudem mit der Analyse von Prozess- und Entscheidungsmodellen.
Der Autor: Kimon Batoulis ist wissenschaftlicher Mitarbeiter und Doktorand in der Business Process Technology Group des Hasso-Plattner-Instituts. Dort unterrichtet er seit über vier Jahren Process Mining und Business Process Management. In seiner Forschung beschäftigt er sich zudem mit der Analyse von Prozess- und Entscheidungsmodellen.